
主成分分析がいかにして固有値問題へと帰着されるのか、詳しめに解説してみる。少し数式が多め。
目次
主成分分析とは?
主成分分析とは、”与えられたデータ情報の次元を圧縮する手法”の一つである。
データの次元を圧縮するとはどういうことだろうか?実は日常生活でもデータを低次元化するということはよく行われている。例えば、肥満度を測るためのBMIという指標が存在する。BMIは体重÷(身長)^2という計算式で導出されるものであるが、よく考えてみると元のデータは(身長,体重)という2成分を持つデータであったのに対し、BMIはただ1成分の数値となっている。これが次元の圧縮であり、情報を削ぎ落としたにも関わらず、肥満度という特徴を表すのに十分な情報を持っている。このように、データに適切な処理を行えば、情報量の削減と特徴の抽出を同時に行う事ができる。また、人がイメージできないような高次元データも、3次元以下に圧縮すればグラフとして描画できるようになる、といったメリットもある。
しかし、現実問題ではBMIの場合のように特徴量があらかじめわかっている場合だけではない。そこで、与えられたデータの傾向から自動的に特徴量を見つけ出し、その特徴を良く表す低次元データへと次元圧縮を行うのが「主成分分析」である。(これはある種の機械学習であり、特に自動的に特徴量を見出すという点において、「教師なし学習」と分類されるものである)。
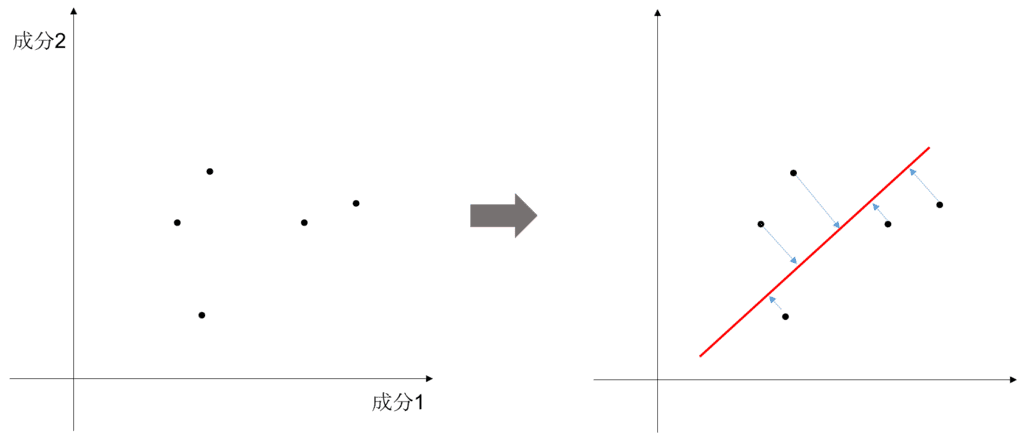
具体的にどのように次元圧縮を行えばいいのだろうか?簡単に、二次元のデータを一次元へと圧縮する場合を考えてみよう。二成分の数値を一成分へと変換する計算式など無数に存在しそうだが、ここでは図のように、データを二次元平面にプロットした時に何らかの直線に向かって全データを射影するという方法を考えることにする。射影した結果、直線の垂直方向の情報が完全に失われ、平行方向の情報のみの一次元データが残る。この残された情報が出来るだけ元データの特徴を良く表していて欲しい。この時、残された一次元データがなるべくバラついている、つまり分散の値が大きいほどよいのである。なぜなら、バラついているということは、各データ点1つ1つの違いをより多く情報として保っていることになるからである。逆に言えば、バラツキの少ない方向というのは、各データが共通して持っている自明な情報なので削除してしまっても問題ないのである。
まとめると、主成分分析では、データの次元圧縮を行う。その際、圧縮後のデータの分散が大きくなるような射影をすることで、特徴量を自動的に抽出するのである。
共分散行列?固有値問題?
統計や数学の勉強を始めると、何に使うのかよくわからない概念が数多く出て来る。
例えば、統計学の教科書や授業などでは「分散」や「共分散」という概念を習う。
「分散」とは、ある一次元のデータ
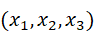
に対して、平均値x¯からの差の二乗和の平均である。式で書けば次のようになる。
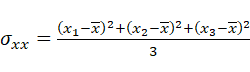
「共分散」とは、ある多次元のデータ
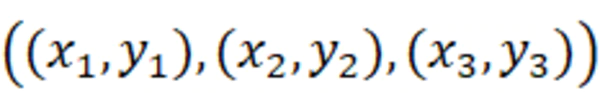
に対して、平均x¯またはy¯からの差、の積平均にあたる。式で書けば次のようになる。
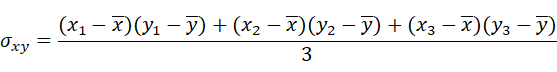
分散は式や定義から、データのバラつきを表していることが直感的にわかる。また、共分散はすぐにはわかりづらいが、xデータとyデータの相関度合いを示すものである。続いて、これらを要素として並べた「共分散行列」なるものが存在する。
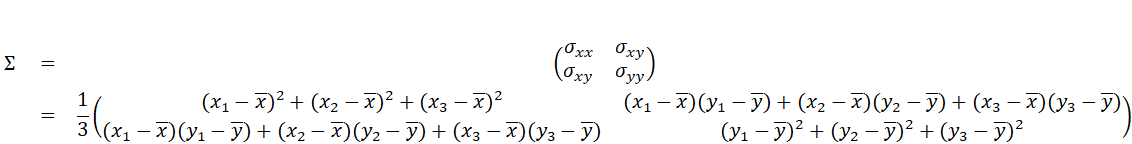
といった感じである。行列の形に並べて何の意味があるのか、筆者自身も最近までその使い道を知らなかった。
他には、数学の線型代数において、何らかの行列を与えられた時に固有値と固有ベクトルを求めるという「固有値問題」がよく登場する。
突然なんらかの行列、例えば
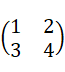
が与えられた時、次の固有方程式
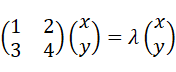
を満たす固有値λと固有ベクトル
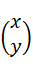
を求めよ、といった具合である。しかし、数学として固有方程式を解く方法だけ学んだとしても、結局何のためにあるのかわからないまま終わってしまう。
これら二つの謎概念(共分散行列、固有値問題)を応用する例の1つが「主成分分析」なのである。
共分散行列についての固有方程式
問題設定
ここからは具体的なデータ群に対して主成分分析を行ってみよう。
少し数学的にはなるが、流れはいたって単純で、
- ある方向に射影した時のデータの分散を計算する
- 分散が最大になるような方向を見つける
を行うだけである。結論としては、1を行うと共分散行列が出現し、2を行うとその共分散行列に対する固有方程式が得られる。
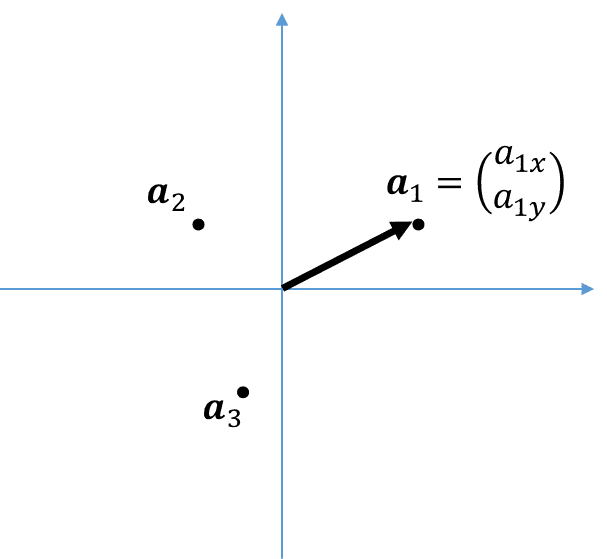
シンプルな例として、3つの二次元データ
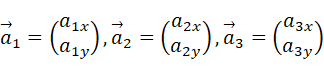
についての主成分分析を考えてみよう。簡単のため、重心が原点(0,0)となるようなデータであるとしている。(このように仮定しても問題ないことは最後まで読めばわかるはず)
準備
今後のために、次のようにデータ成分を並べた行列を定義しておく。
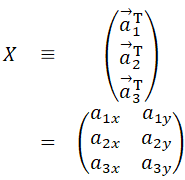
転置行列

との積
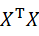
を計算してみると、
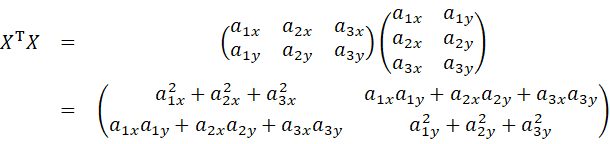
最終的な表式が、上で見た共分散行列の形になっていることがわかる(“1/データ数”の因子を除いて)。共分散行列は後で出てくるので、次のようにΣとして定義しておこう。
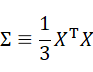
1. 単位ベクトルにデータを射影した時の分散を計算

ある方向の単位ベクトルを
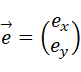
と表す。
データを
の方向に射影して、1次元データとなった後の分散値の表式を求める。例えば、
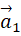
を
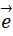
に射影した値は

のようにベクトルの内積を取ることで簡単に計算でき、これを用いて分散(var)を定義通りに計算すると、

となる(平均値は0となっていることに注意)。これを行列の積の形に分解して表現してみると、次に示す式の一行目のようになる。実は、この分解した行列がそれぞれ
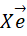
とその転置行列
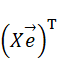
になっている(実際に計算してみれば確認できる)。二行目から三行目では行列の性質を用いている。こうすると
という並びが出現する。これは上で計算した共分散行列Σである。
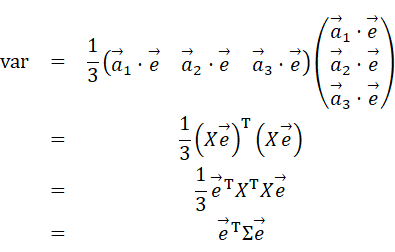
このvarの表式はデータが多成分(つまり高次元)、多データ化しても一般的に成り立つはずである。なぜなら、行列Xやベクトル
の縦成分と横成分数をデータ次元数とデータ数に併せて拡張すれば同じような計算が行えるからである。
2. varが最大になる方向を求める
さて、主成分分析ではこのvarを最大化するような
を求めることが目的であった。また、
には単位ベクトル、つまりノルムが1であるという制約条件も付いている。このように、ある制約条件のもとで、関数の最大(最小)を決定する時には、「ラグランジュの未定乗数法」というものがよく用いられる。
ラグランジュの未定乗数法:
変数x,yについて、「g(x,y)=0」の制約条件下で「f(x,y)」という関数を最大(小)化するのは、
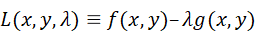
という関数を定義した時に、
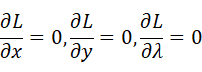
であり、これらが0になるので

を満たすような解(x,y)である。
ラグランジュの未定乗数法を用いると、
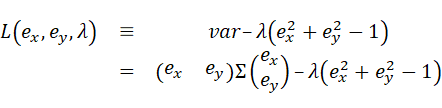
と定義した関数

に対して
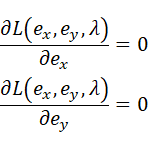
が成立するようなex,eyを見つければよい(λについての偏微分は一旦無視する)。
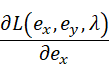 、
、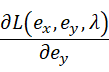
を計算すると、
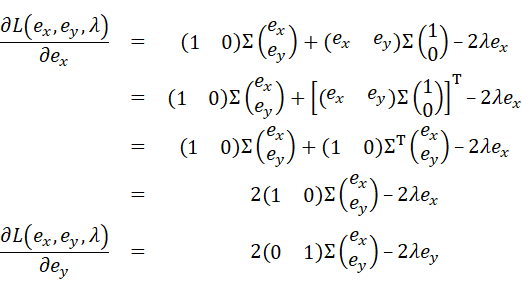
であり、これらが0になるので
と式変形出来る。2つの方程式をまとめると、
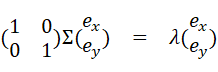
一番左の行列はただの単位行列なので省略して、
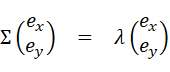
これは共分散行列Σに対する固有方程式となっている!! (上で無視していた)
つまり
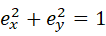
というベクトルの正規化条件は、固有値問題を解いた後の固有ベクトルを拡大縮小することで調節出来る。) 実際にデータを主成分分析する際には、データから共分散行列を生成し、固有ベクトルを計算、全データを射影する、といった作業を行えば良い。プログラミング言語によってはこれらの作業を簡略化出来るパッケージが存在したりするので、とても簡単に処理出来る。
(追記 11/20) 上で最終的に導出した固有方程式は2×2の行列についてのものなので、固有値λと固有ベクトルeは2種類出現する(重解などの可能性はあるけれど)。この時、求めたかった主成分の軸を表すのは2つの固有値,固有ベクトルの内どちらなのだろうか。
これは簡単に決めることが出来る。手に入れた固有方程式

の表式から、分散varをさらに計算してみる。
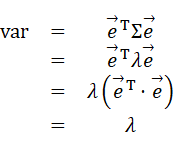
λつまり、固有値λは分散varの値そのものだったのである。主成分分析では分散varを最大化することが目的であったので、固有値λは2つの内大きい方を選択すれば良いのである。
参考リンク
主成分分析に関しては、以下の解説およびブログを参照した。
いかがでしたでしょうか?最後までご覧くださりありがとうございました。
